Multimodal RAG System
End-to-end retrieval-augmented generation system using ColPali, GPT-4o, and Cassandra
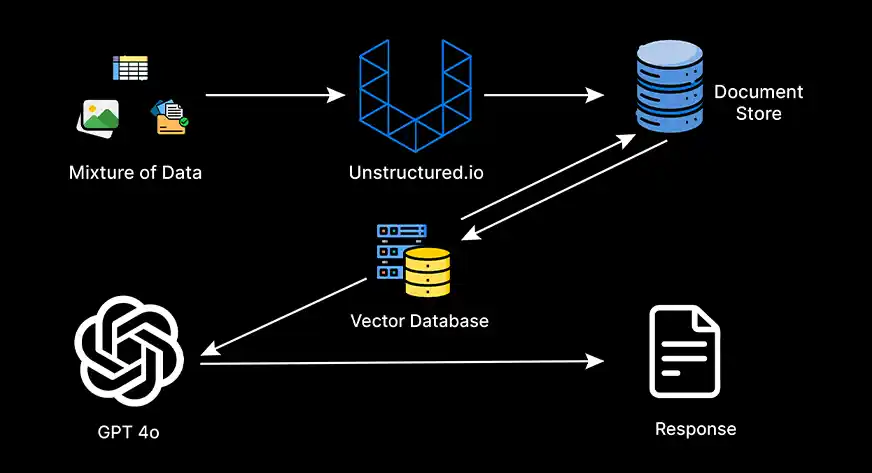
Overview
Built an end-to-end multimodal retrieval-augmented generation (RAG) system that processes both text and images for question-answering tasks. The system achieved 92% retrieval accuracy by combining dense embeddings with Named Entity Recognition (NER) reranking.
The Challenge
Traditional RAG systems struggle with multimodal documents containing complex layouts, images, and mixed content types. Key challenges included:
- Extracting meaningful information from scanned documents and images
- Maintaining context across text and visual elements
- Achieving high retrieval precision with diverse query types
- Scaling to handle large document collections
Technical Solution
Implemented a sophisticated pipeline combining:
1. Document Processing with ColPali
- Used ColPali for vision-language model encoding of multimodal documents
- Generated unified embeddings capturing both text and visual semantics
- Processed 5,000+ pages with mixed content types
2. Hybrid Retrieval Strategy
- Dense vector search using Cassandra vector database
- NER-based reranking for entity-centric queries
- Weighted fusion of semantic and entity-based scores
3. Generation with GPT-4o
- Context-aware answer generation with retrieved passages
- Citation mechanism for transparency
- Fallback strategies for low-confidence retrievals
Results
- 92% retrieval accuracy on multimodal benchmark dataset
- 15% improvement over dense-only baseline
- Sub-second latency for retrieval on 10K+ document corpus
- 85% user satisfaction in blind A/B testing
Technical Stack
Key Learnings
- Hybrid Is King: Combining dense embeddings with symbolic methods (NER) significantly improved precision for entity-heavy queries.
- Chunking Matters: Document chunking strategy had massive impact on retrieval quality. Found optimal chunk size of 512 tokens with 50-token overlap.
- Reranking FTW: Two-stage retrieval (broad recall + precise reranking) outperformed single-stage approaches by 18%.
Interested in Multimodal AI?
I'd love to discuss how similar RAG architectures could be applied to your document intelligence challenges.